分析一个 rate-limiter 漏桶算法的实现机制
服务治理的面试中常被问到,面对突发流量如何应对,通常都是回答限流或则降级。再追问一句限流算法有哪些,通常都是会说令牌桶或者漏桶算法。原理说说容易,但到了实现层面,大多是找一个现成的开源实现,例如 uber-go/ratelimit: A Golang blocking leaky-bucket rate limit implementation (github.com) 。今天花了一点时间认真研究了一个限流算法的实现,记录下来免得日后忘了。
漏桶算法原理
漏桶算法 原理本身非常好理解,有一个用来盛水的桶,下面有一个开口。上方自来水龙头表示 请求,请求可以任意速率加入到桶里,但下面的小空保证了桶内的水会以恒定的速率往下漏 (表示具体访问到业务层) 。 如果自来水的流水速度超过了下漏的速率,就会从桶溢出 (表示抛弃这个请求),具体看下图
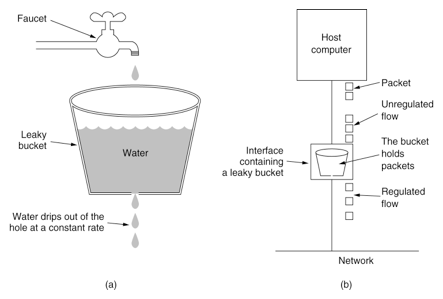
漏桶算法的主要作用是削峰,无论外部请求以怎样的速率 (QPS) 进来,总是能够以恒定的速率来访问下游的服务,起到对服务保护的作用。
核心要素
在分析具体实现前,我们先看下漏桶算法的核心要素有哪些。首先有2个关键的系数,capacity 表示桶的容量,当capacity 满了的时候,就会抛弃这些请求。另外一个是 leak_rate 下漏的速率,通常单位可以是 req/s ,表示每秒放过多少 request 到下游
Time 时序
除了 capacity 和 leak_rate , 有一个最容易遗漏的概念就是 (timestamp),漏桶算法 的背后也是一个时序 (time-series) 的模型,因为请求是按照时间先后进来的,漏出自然也会根据时间先后来漏出。
实现
这里全程都用 python 来做代码实现。假设我们在一个 python 的 webserver 上希望通过漏桶算法实现限流,大概的实现是这样的:
1 | def request_handler(self): |
今天这个实现会比较特殊,不考虑 capacity 的情况,分两个场景
- 可以漏出
- 不能漏出,阻塞继续排队等或者直接抛弃
先来看这个 LeakBucket 的设计
1 | class LeakyBucket(object): |
这里主要是用了 self._que 来存储请求时间的队列,按照请求时间的先后顺序依次插入。加了一个self._lock 用来处理多线程场景下的数据一致性。
原理说明
先看下核心函数 acquire 的实现,
1 | def acquire(self, block=True): |
再结合下面这个原理图,尝试做下分析。
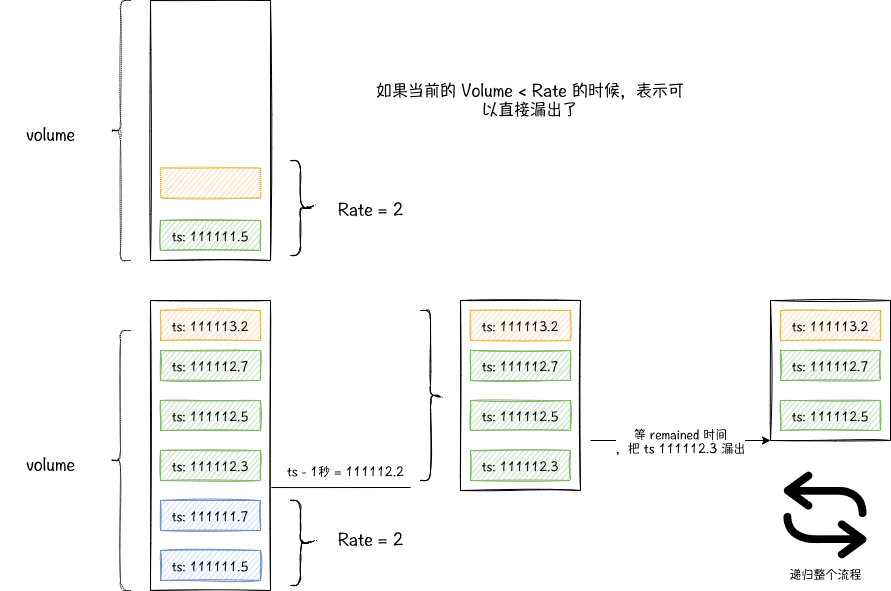
因为是一个新的请求,所以它的时序就是 now 当前最新时间。volume 表示当前 queue 的长度。这里加了一把锁是用于多线程的场景,锁的粒度有点大,先不管了。
首先看判断 if volume >= self.leaky_rate, 如果 volume 没有 leaky_rate 大,表示当前桶没满,且可以字节漏出,那就在第22行,把自己 append 到 queue 中,然后直接返回 True 就好了。
反之,表示容量是超过漏出的速率的,我们看到这个时候,是通过 pre_tick 来获取前一秒时间窗口,通过 self.inspect_expired_items(pre_tick) 这个函数来获取哪些请求已经漏出了,这里我们看下 inspect_expired_items 这个函数的实现
1 | def inspect_expired_items(self, time: int): |
它的主要作用就是遍历整个 queue 找到时序比传入的时间参数大的第一个请求,通过 volume - log_idx 计算有多少个请求应该漏出了 (注意这里是应该,而不是已经),另外第一个未漏出请求的剩余时间。(这里大家可能会和我有一样的质疑,为啥 > time 就表示还未漏出,这里后面会介绍)。
再回到 acquire 函数的第15行,如果 item_count > leak_rate 表示这些应该漏出的请求也还在排队,那我们就等一个最小时间 remaining_time, 然后继续通过递归来判断是否可以漏出了。
我们最后看下 22 行,这里是当我们判断可以漏出的时候,会把之前的数据清除掉,这就回答了前面的问题,为啥在inspect_expired_items 里只要判断时序大于参数 time 就可以表示应该漏出了。
总结
写的听绕的,😅