理解 LSM 树: 用于多写场景下的数据库实现
本文翻译自 “What are sparse and dense indexes? (yetanotherdevblog.com)“
日志结构的聚合树 (Log-Structured Merge-Tree) 是一种典型用来处理存在很重的写操作的时候的数据结构。任意写的操作被优化成了顺序写。LSM tree 是很多数据库背后的核心数据结构,包括 BigTable, Cassandra,[Scylla](ScyllaDB | The Real-Time Big Data Database) 和 RockDB 。
SSTable
LSM Tree 使用一种可以理解为基于字符串排序的表 (SSTable) 来在磁盘上进行持久化。从字面意思来看,SSTable 是一种用来存储 key-value 键值对的格式,而且它的 key 是已经排序过的。一个 SSTable 有多个排序过文件组成,它们叫做 Segments。这些 Segments 一旦被写入磁盘就不能被修改。一个简单的实例如下图:
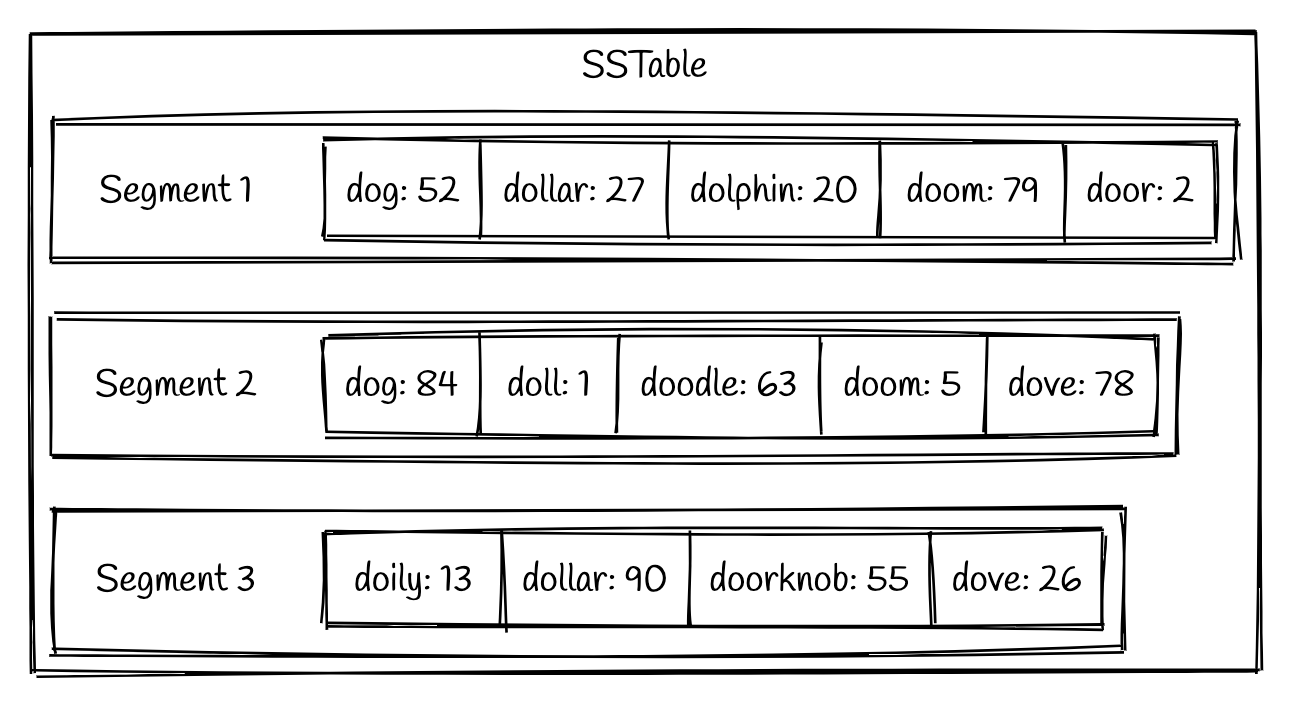
可以看到每个segment 中的 key-value 对都是基于 key 排序的。我们将在下一章节介绍 segment 到底是什么,以及它是如何生成的。
写数据
回忆前文,LSM 树只会进行顺序写。我们可能会怀疑因为实际的数据是无序写入的,我们如何保证顺序写且有序呢?这个问题通过在内存中构建一个树形的数据结构来解决。这个通常被称作 memtable (内部表),但是它背后的数据结构通常是一个排序树,例如 红黑树 。当数据被写入的时候,它被添加到了红黑树中,
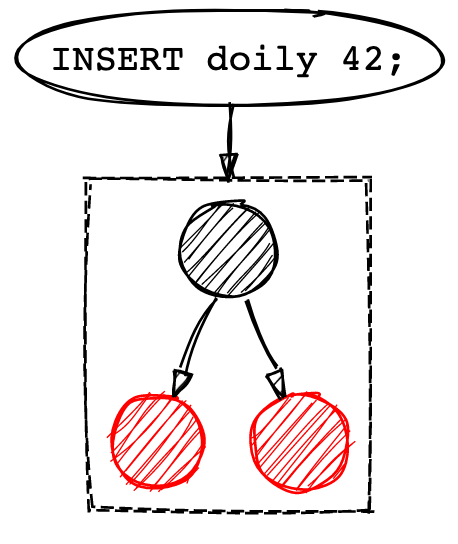
我们的写入数据都被存入这棵红黑树中,直到容量达到了我们预设值。一旦红黑树达到了容量上限,它就会把数据通过 segment 以有序的形式刷新到磁盘上。这个允许我们在写入 segment 文件的时候保证单点顺序写即使外部数据进入时候是无需的。
读数据
那我们如何在 SStable 中查找数据的呢?最直观的方式就是直接扫描 segments 文件,寻找需要的 key 。我们可以从最新的 segement 开始寻找,从新到旧直到我们找到那个 key 。这种方式意味着越是最新写入的数据,我们可以更快查询到。一种简单的优化方式是在内存中维护一个稀疏索引 (sparse index)
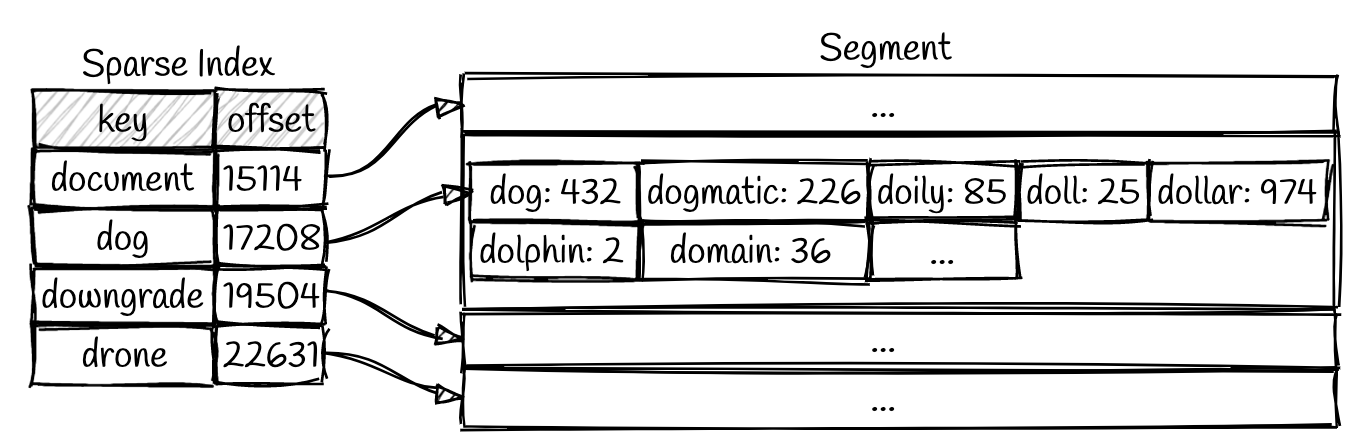
通过这个索引,我们可以快速定位到要插入 value 对应的 key 所处于下标的上下界位置。现在我们只要针对这个区间内的所有 segment 进行小范围的扫描就好了。例如这个场景,我们要寻找 dollar 这个 key 在示例 segment 中的位置。我们可以在稀疏索引中通过二分查找发现 dollar 处于 dog 和 downgrade 之间。现在我们只要遍历下标从 17208 到 19504 就可以找到这个 key 对应的 value (或者判断是否缺失)
这是一个很不错的优化,但是如果是一个不存在的 key 呢?我们最终可能会去遍历每一个 segment file 但不能找到那个 key 。这里 布隆过滤器 (bloom filter) 可以帮助我们避免这个问题。bloom filter 是一种空间优化的数据结构用来回答数据是否存在于当前数据集的问题。我们可以在每次写入数据的时候把它添加到 bloom filter 中。每次在读开始的时候先检查是否存在从而可以提升对于不存在 key 的响应效率。
Compaction
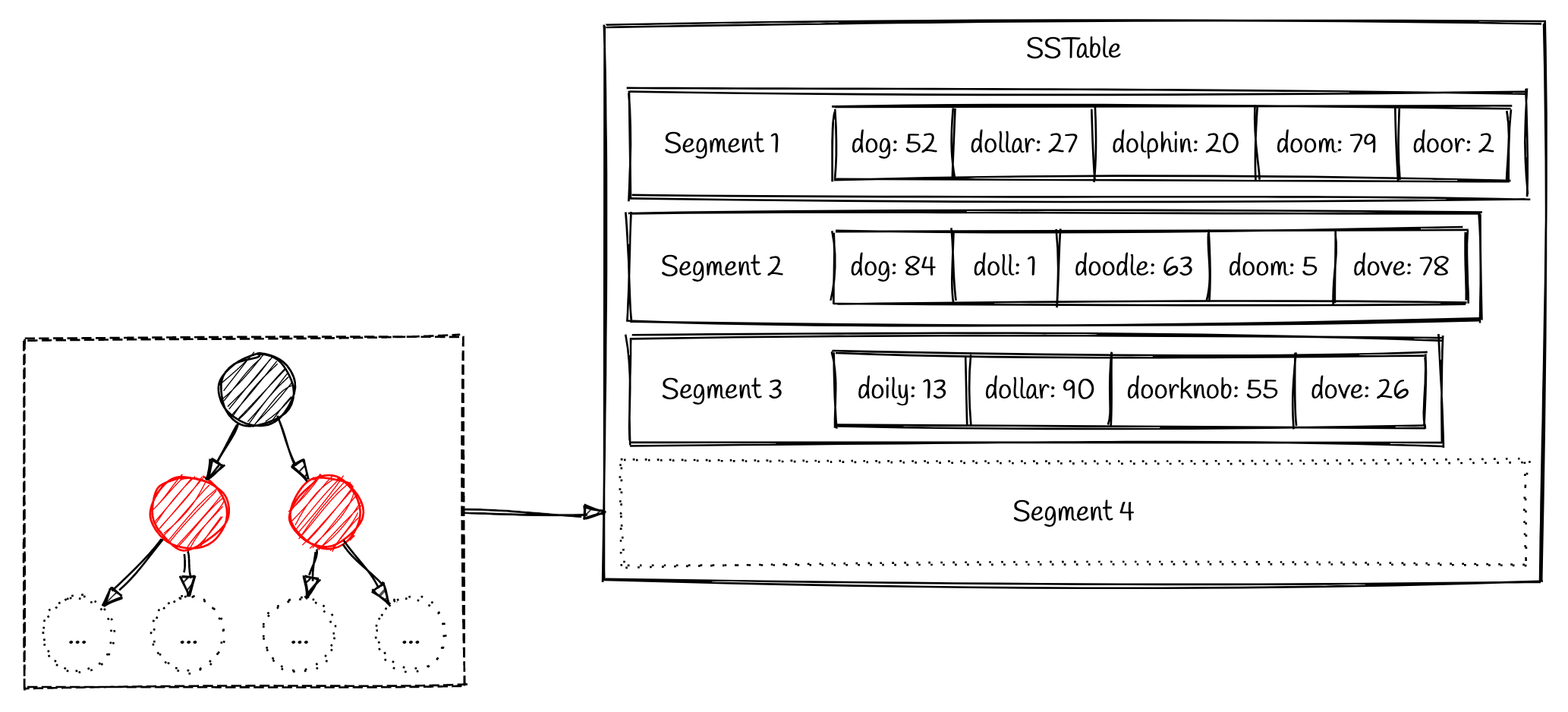
随着系统的持续运行,久而久之系统会积累大量的 segment 文件。这些 segment 文件需要被清理和维护避免数量达到我们无法控制的规模。这个就是一个叫 compaction (精简) 进程的责任。Compaction 是一个后台进程,它持续合并旧的 segment 成新的 segment
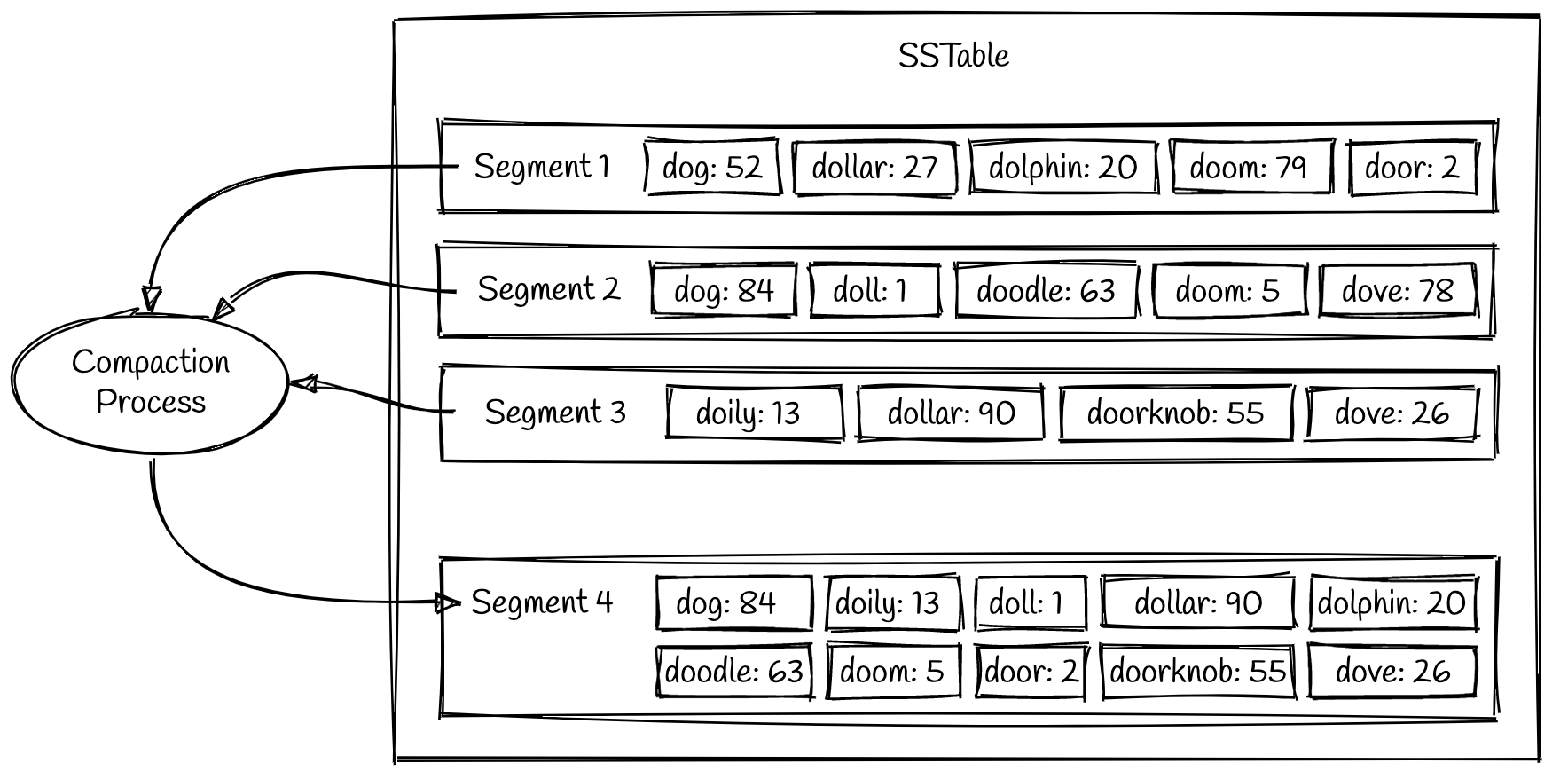
可以看到上面的例子里,segments 1 和 2 都有一个共同的 key 叫 dog 。相对新一点的 segment (2) 包含最新的值,所以 segment 2 中包含的值会被带入到新的 segment 4 中。一旦 compaction 完成合并的工作,旧的 segment 会被删除。
删除数据
我们已经讲完了读和写入数据,那么如何删除数据呢?因为 Segment file 被认为是不可修改的,我们如何删除 SSTable 中的数据呢?删除实际上和写入是一样的方式。当发生了一个删除的操作,一个叫 tombstone 的标志位会被写入在那个 key 上
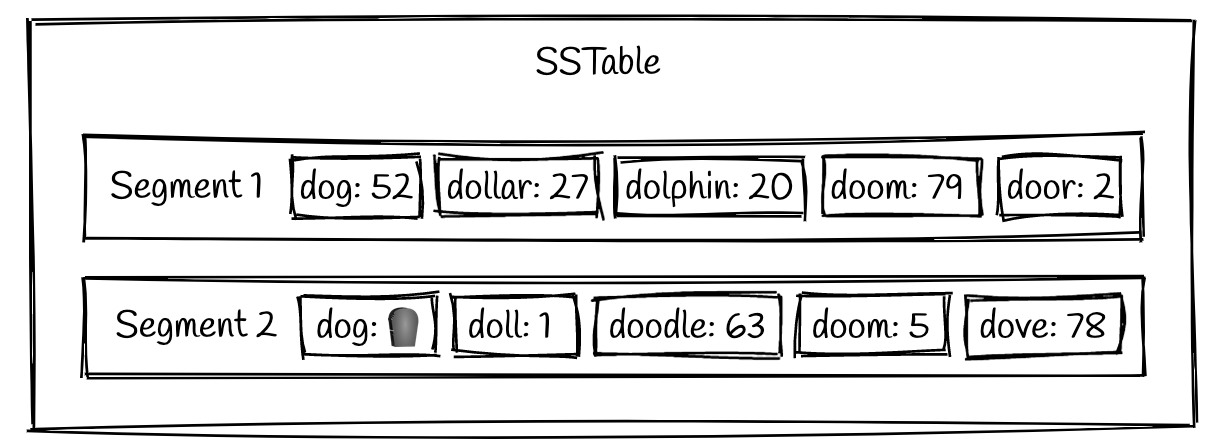
上面这个例子里可以看到 key dog 有一个历史数据 52, 但是最新的 segment 里有一个 tombstone 的标志位。这个表明如果我们收到一个 dog 的读请求,我们要返回它不存在。这个意味着删除的操作在一开始仍然会占用磁盘的空间,这个可能会让很多开发者觉得惊讶。最终 tombstone 会随着 comaption 被从磁盘上删除。
总结
到这里我们能够理解一个基本的 LSM tree 存储引擎的工作原理了
- 写操作被存储在一个内存的树结构中 (也叫做 memtable) 。 支撑性的数据结构 (布隆过滤器 bloom filter 和 稀疏索引 sparse index) 也会被同步更新。
- 当 memtable 变得太大就会被按有序 key 的方式刷入磁盘
- 当来了一个读请求,我们会先检查 bloom filter。 如果 bloom filter 显示不存在,我们就会返回给客户端 key not found 。如果 bloom filter 提示存在,我们就根据 segment 文件从新到旧来遍历查询。
- 每个 segment file,我们先查询稀疏索引,然后在 key 所在的范围,根据下标来遍历直到我们找到那个 key,最终把 value 返回给到客户端。